Aug 24, 2025
Saurabh Singh
Founding Engineer
Stages of Cold Start
Complete cold start time consists of two stages:- Node provisioning: When autoscaling from zero or adding nodes, cloud providers take 80-120 seconds to provision and boot new GPU instances. This is entirely cloud-dependent and outside user control.
- Container start: Time to pull container image from registry, extract layers, and start the container.
Lazy Loading the filesystem
Analysis shows that for typical AI workloads, 76% of startup time is spent downloading container images, yet only 6.4% of image data is accessed during application startup. This extreme inefficiency creates an optimization opportunity: defer downloading unused files until actually accessed.Snapshotter Mechanisms
Snapshotters are containerd components that manage filesystem layers for containers. They determine when and how image data is retrieved from registries. The default snapshotter is called overlayfs. Some open source lazy loading snapshotters are Nydus, SOCI and eStarGZ.Expected Gains
When using a lazy loading snapshotter, the startup time for containers falls drastically. From our experiments with fastpull, the initial gains lead to container startup times decreasing from minutes to seconds. This is a substantial gain, but as we see in the sections below, the gains we see initially degrade at every stage, leading to a much smaller eventual gain.Why do the initial Lazy Loading gains degrade
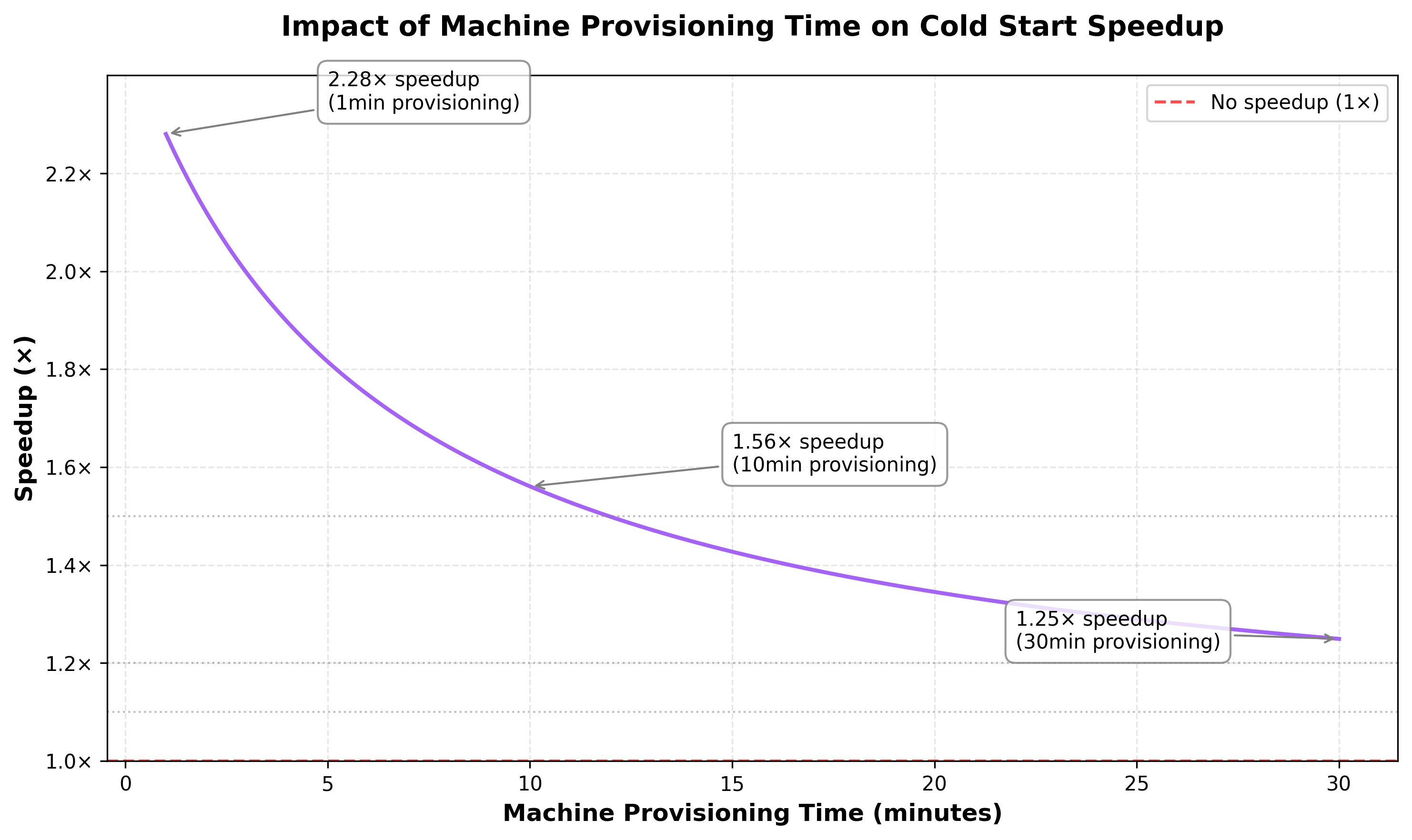
There are two important factors which reduce our initial 100x gain to a more modest 1.5-3x gain:1. Application Startup time:
As AI/ML workloads need to download large models, decompress them, load them into GPU memory and do model compilation, they realistically take several minutes to start up—i.e., on the same order of magnitude as the container startup time. Let’s consider a case where lazy loading should benefit by a large margin. Say the overlayfs container startup time is 10 mins, and lazy container startup time is 1 sec Let’s look at the following graph to understand how this affects the speedup.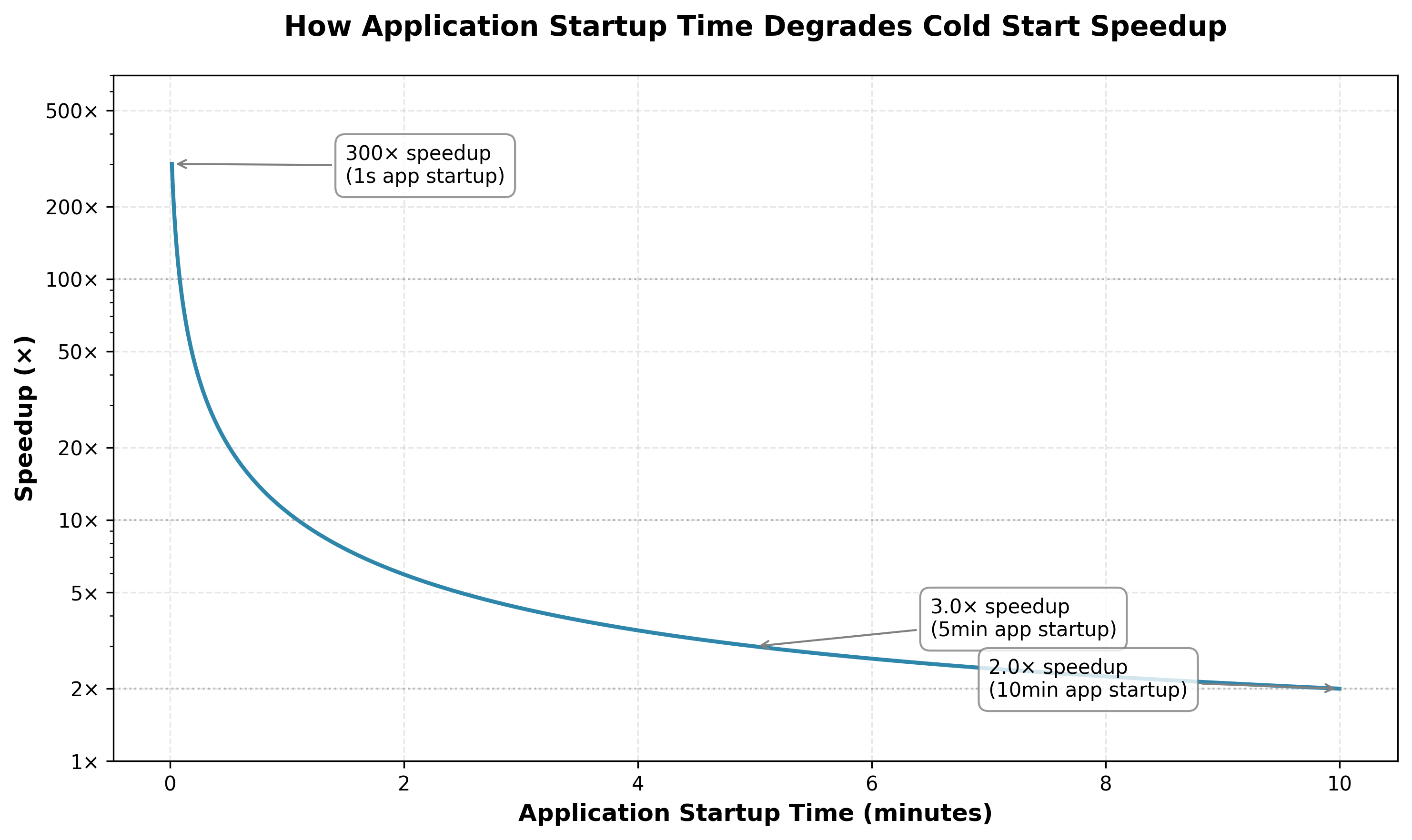
2. Lazy loading Cache Misses:
On a high level, lazy loading starts two processes: one process starts to download all the files for the image from the remote registry, and the second process starts the container and uses the file if it has been downloaded already or fetches it from the remote registry. Thus the first process creates a cache, which the second uses. In an ideal scenario, the first process runs ahead of the second process and has all the files already cached which the container needs. In practice, cache misses occur when the container requests files before they’re downloaded, causing lazy loading application startup times to be slower than overlayfs startup times. For the same example, if the lazy loading application startup is 20% slower than overlayfs startup time, this is how the speedups look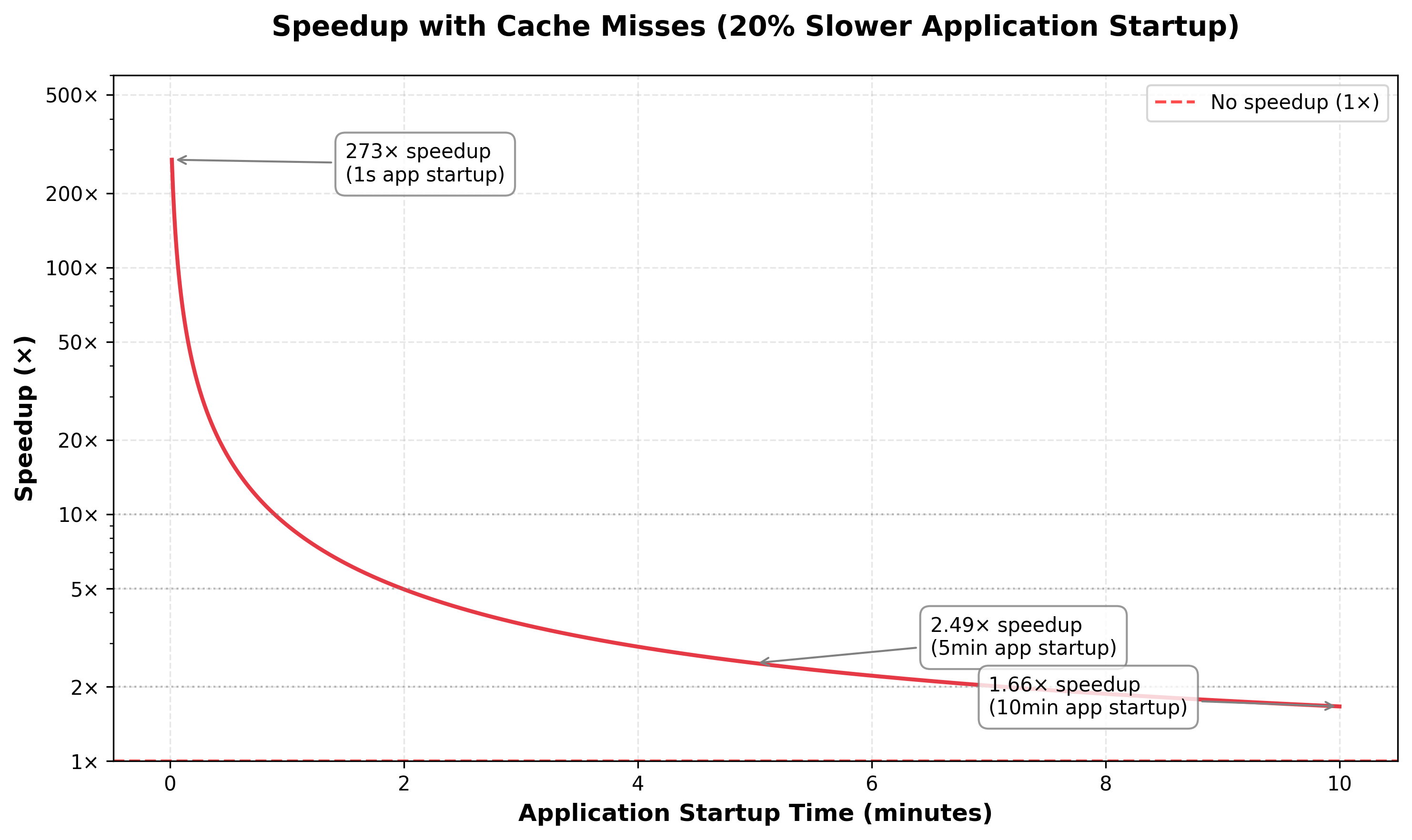
Intrusive Setup
Implementing lazy loading requires significant infrastructure changes:1. CI/CD Changes
The build process now involves converting images from the overlayfs format to the custom snapshotter format. This increases build times, makes incremental builds slower, and requires extensive CI/CD pipeline changes. Maintaining both old and new snapshotter images also increases storage costs. Additionally, you must verify that your registry is compatible with the new snapshotter (e.g., GAR does not support SOCI snapshotter).2. Node Infrastructure Changes
You must install snapshotter plugins on all cluster nodes and configure containerd to use them. Different base OSes require different setup mechanisms, each of which must be tested to ensure optimal performance.3. Testing Overhead
Every converted image must be tested to ensure it behaves identically to the original, and to check if it performs optimally.Provisioning Machines On Demand - A Challenge
Unless one reserves machines, which involves significant capital investment, every node which spins up will take an indefinite amount of time. This time will vary depending on:- The Cloud Provider (your choice of Hyperscaler or a NeoCloud)
- Availability in the region you need the machine in